Teaching data science with the tidyverse
rstudio::conf(2022)
Designing the data science classroom
Setting the scene

Assumption 1:
Teach authentic tools

Assumption 2:
Teach R as the authentic tool
Tidyverse
- Meta R package that loads eight core packages when invoked and also bundles numerous other packages upon installation
- Tidyverse packages share a design philosophy, common grammar, and data structures


Desired output
Break it down I

Break it down II
Break it down III
Break it down IV
Break it down IV
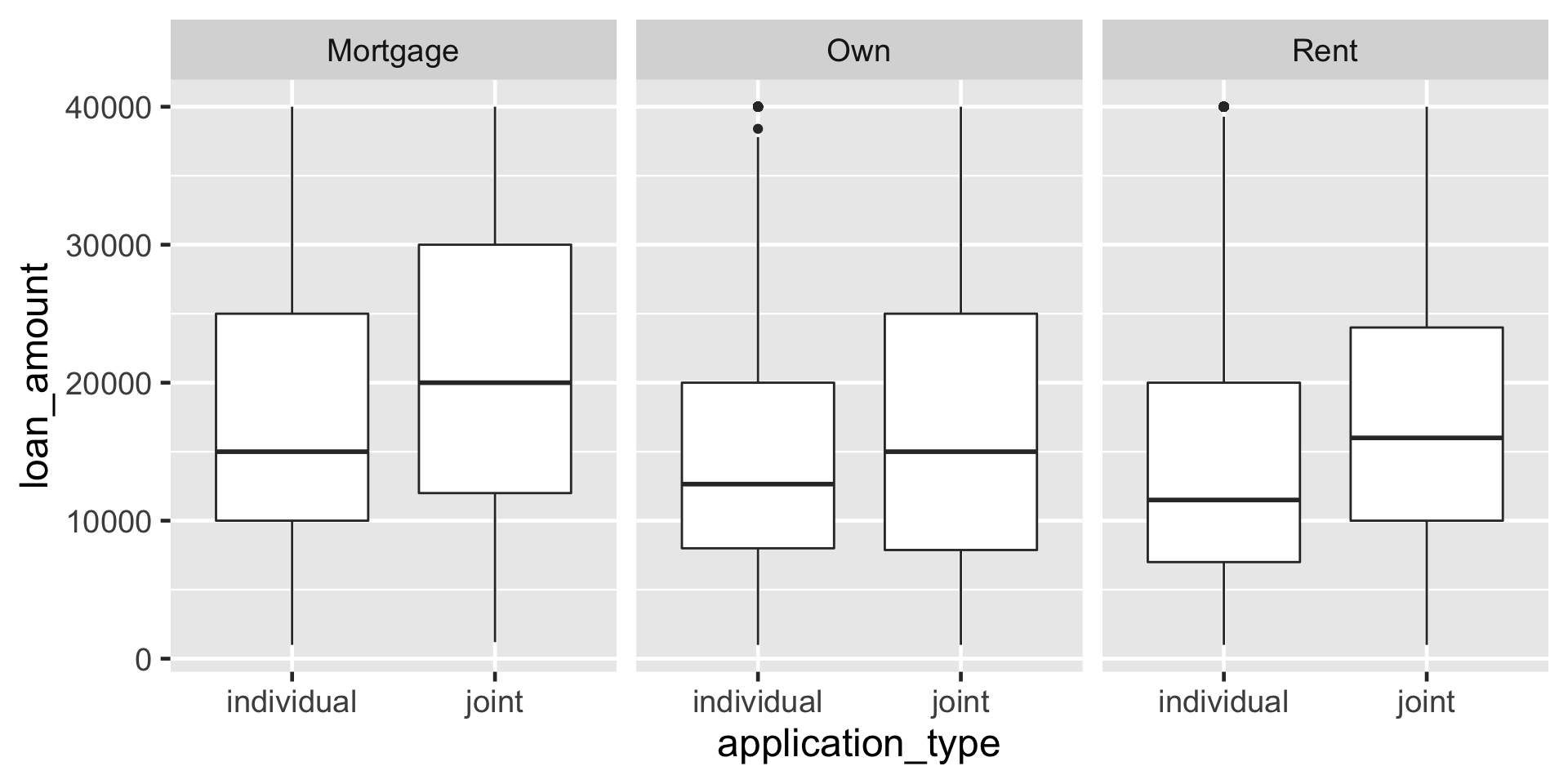
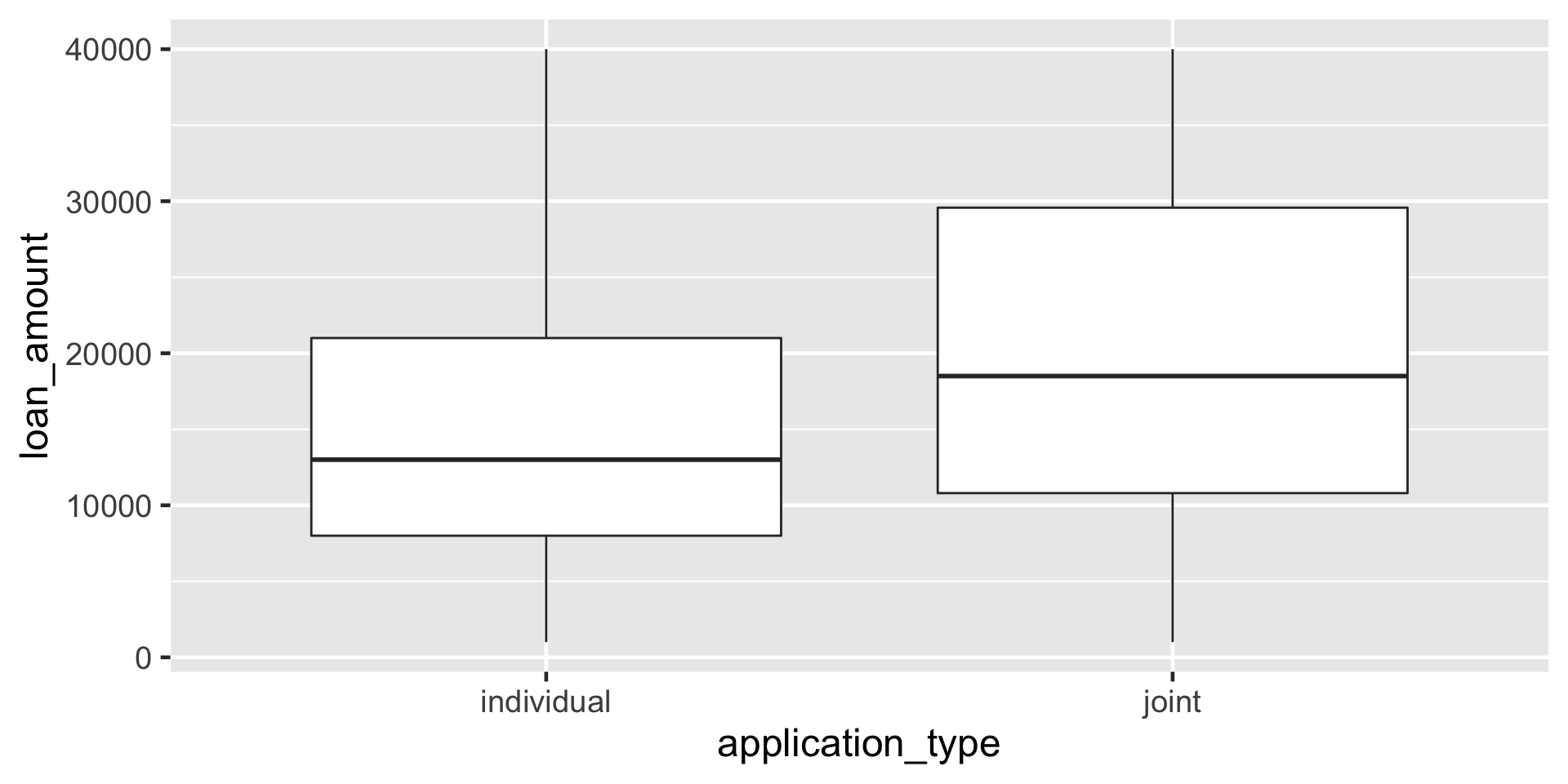
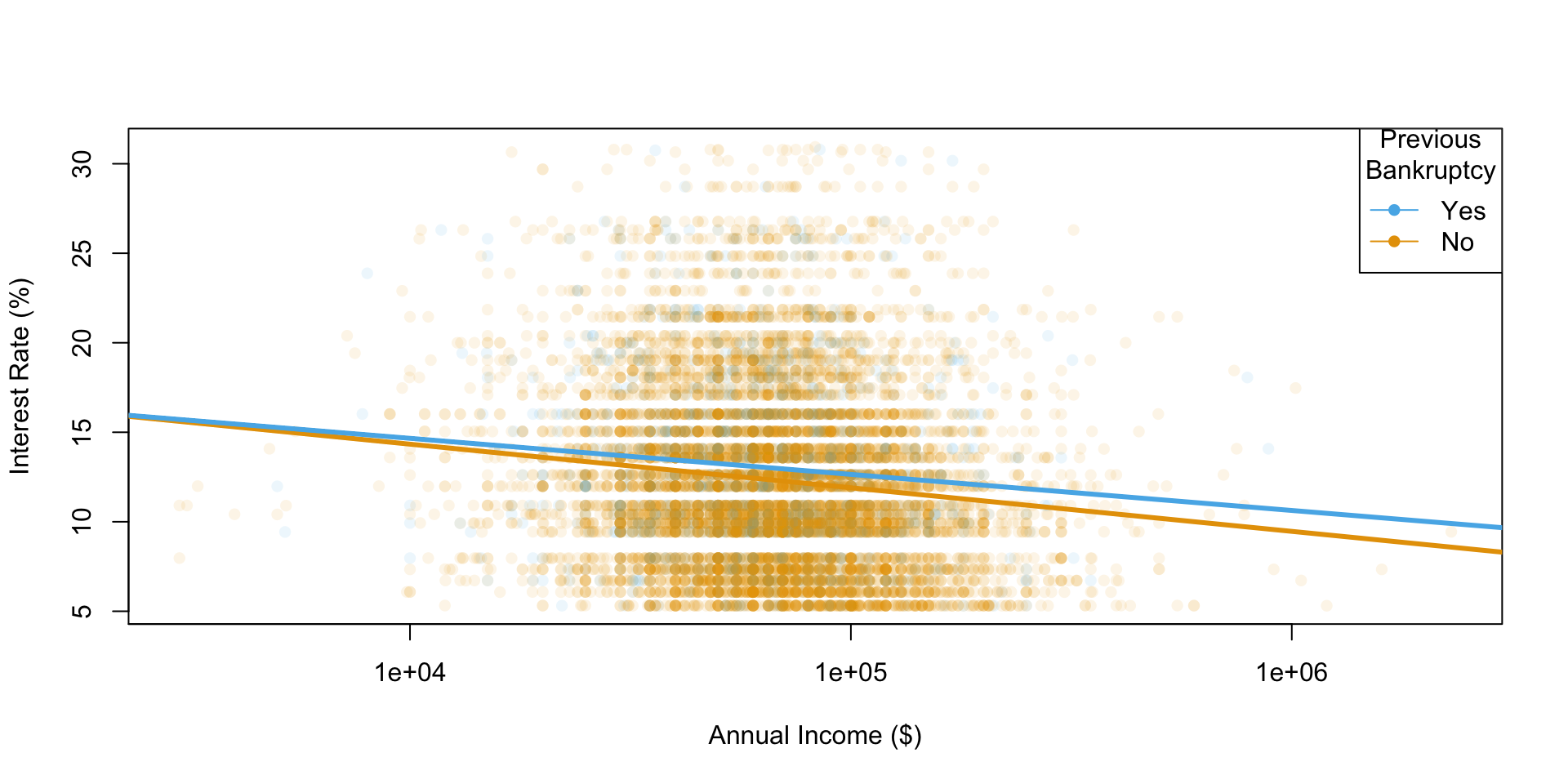
Plotting with boxplot()
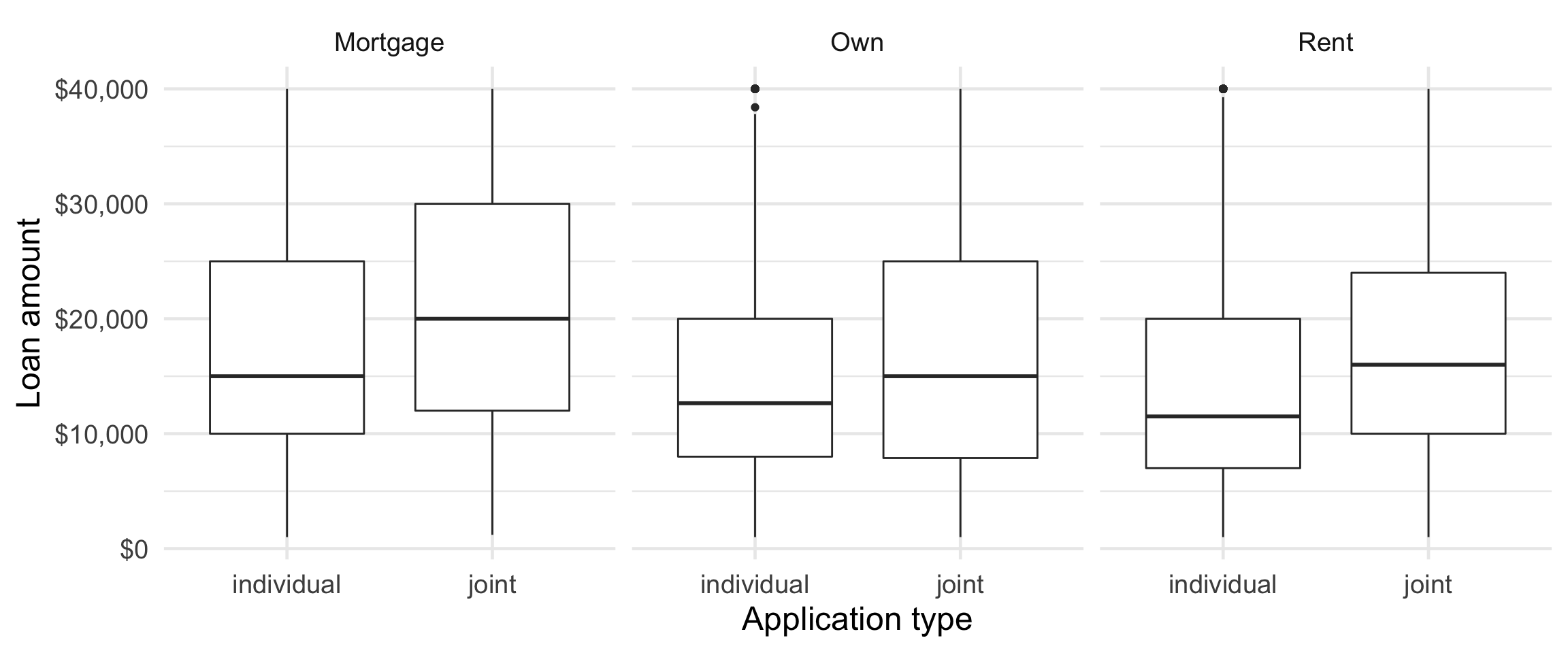
Visualizing a different relationship
Visualize the relationship between interest rate and annual income, conditioned on whether the applicant had a bankruptcy.
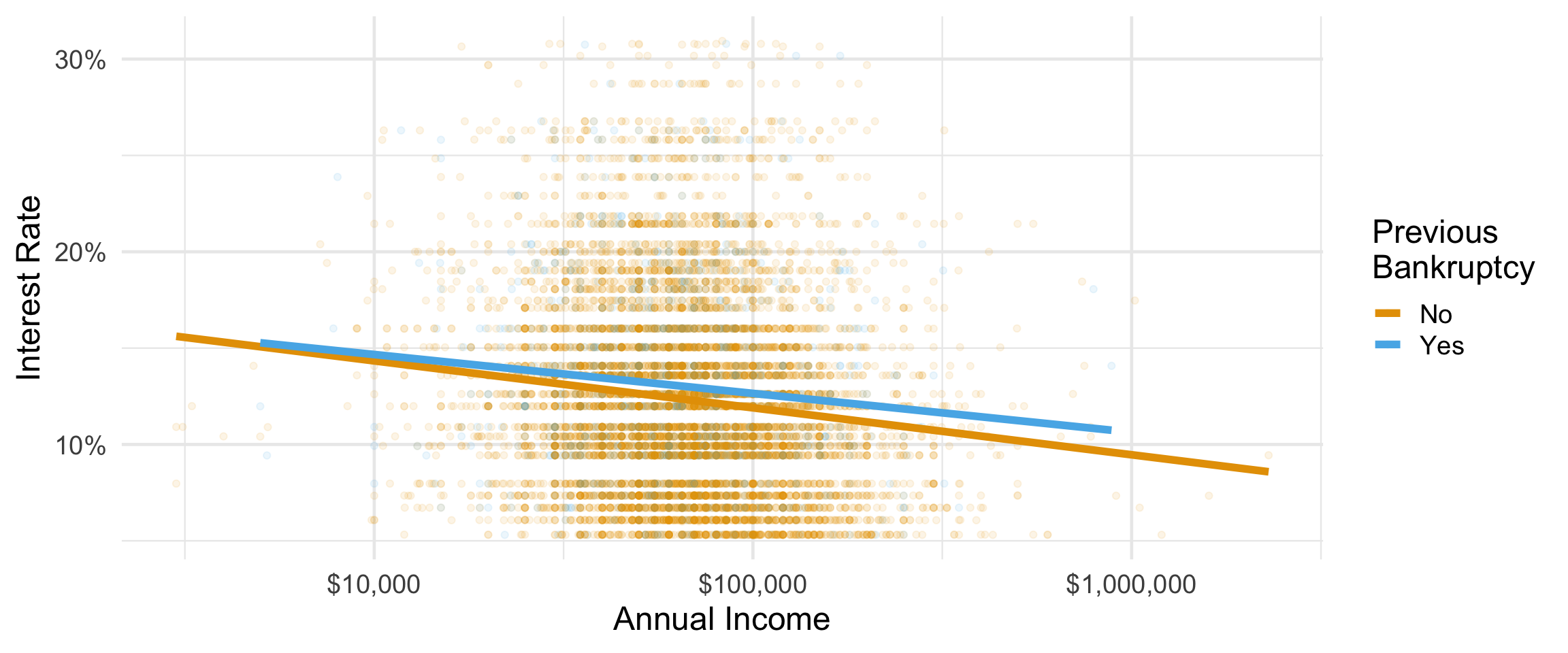
Plotting with ggplot()
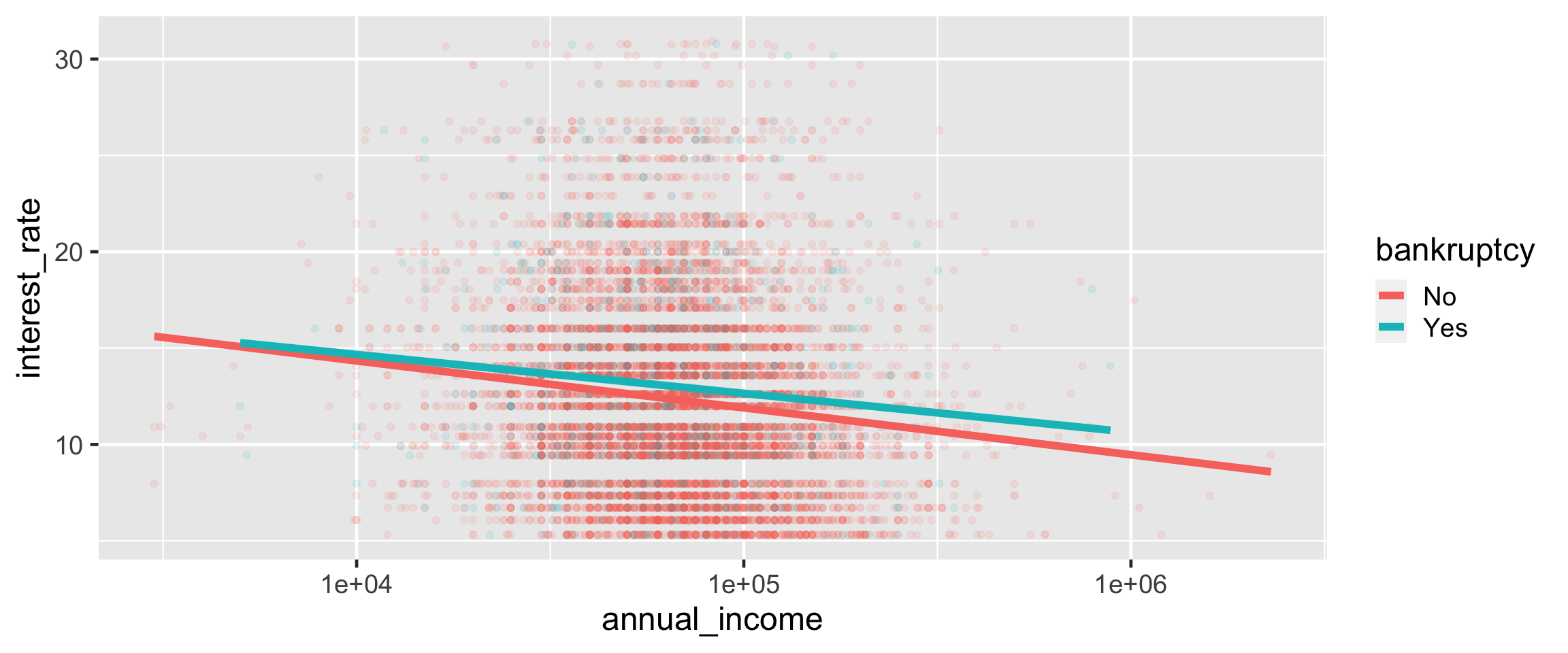
Further customizing ggplot()
ggplot(loans,
aes(y = interest_rate, x = annual_income,
color = bankruptcy)) +
geom_point(alpha = 0.1) +
geom_smooth(method = "lm", size = 2, se = FALSE) +
scale_x_log10(labels = scales::label_dollar()) +
scale_y_continuous(labels = scales::label_percent(scale = 1)) +
scale_color_OkabeIto() +
labs(x = "Annual Income", y = "Interest Rate",
color = "Previous\nBankruptcy") +
theme_minimal(base_size = 18)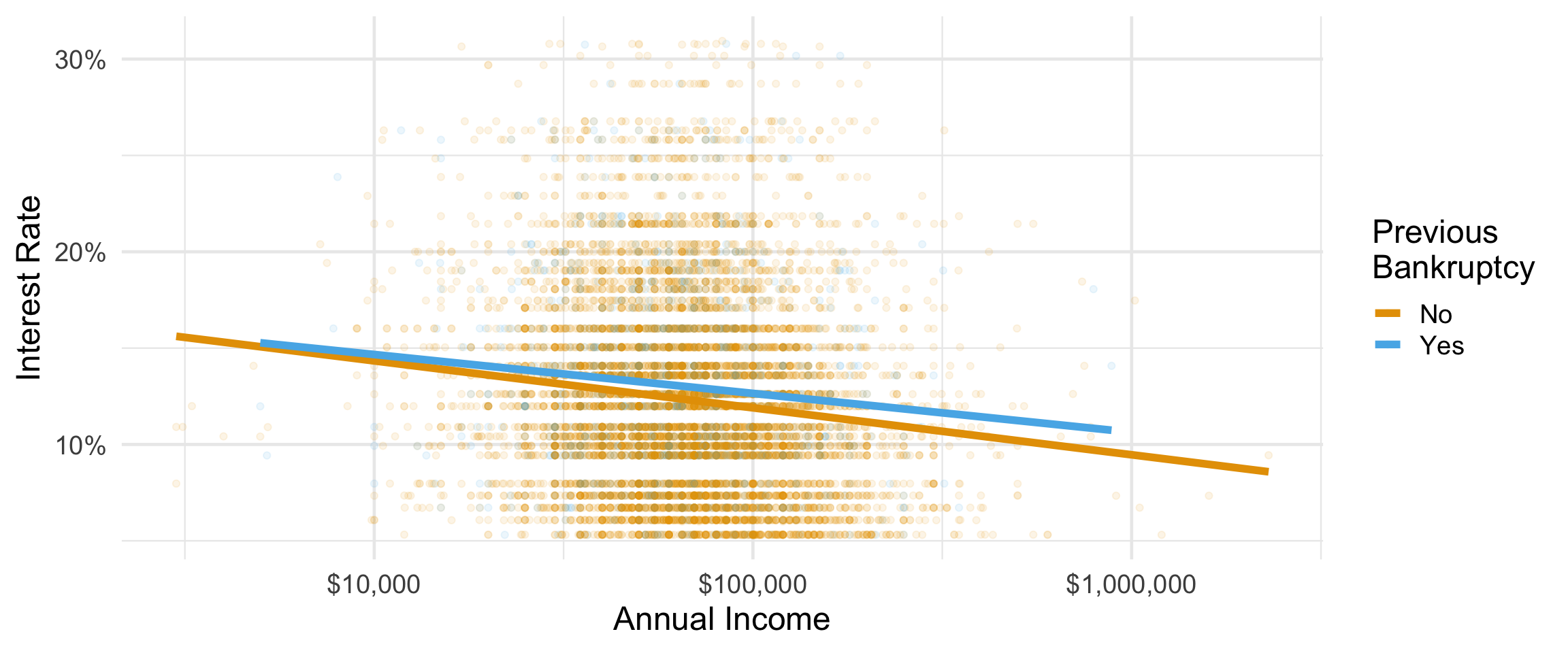
Plotting with plot()
Keeping up with the tidyverse
Blog posts highlight updates, along with the reasoning behind them and worked examples
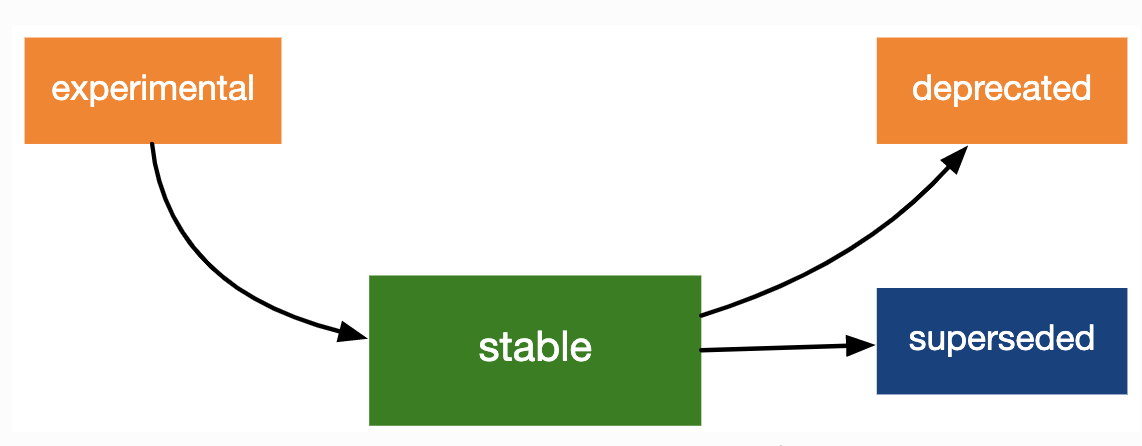
Lifecycle stages and badges
![]()
Coda
We are all converts to the tidyverse and have made a conscious choice to use it in our research and our teaching. We each learned R without the tidyverse and have all spent quite a few years teaching without it at a variety of levels from undergraduate introductory statistics courses to graduate statistical computing courses. This paper is a synthesis of the reasons supporting our tidyverse choice, along with benefits and challenges associated with teaching statistics with the tidyverse.

Time permitting
Let’s take a look at the source code for these slides for some of the highlighting tricks!